Create a Natural Language Question Answering system with IBM Watson Thu, Apr 14, 2016

As you may know Watson is a question answering computer system capable of answering questions posed in natural language,
it developed in IBM’s DeepQA project by a research team led by principal investigator David Ferrucci.
IBM also released it’s cloud platform IBM Bluemix in 2014. It supports several programming languages and services
as well as integrated DevOps to build, run, deploy and manage applications on the cloud.
And of-course Watson API’s are accessible in Bluemix platform.
Before you begin
Before you begin, you need the following pieces
- You need Bluemix account
- Node.js
- Python
Overview of Question Answer System
The final goal is simple; design and develop an application be able to:
- Analyze unstructured data
- Understands complex questions
- Presents answers and solution

But unfortunately, it is not as easy as advertised by IBM. In past IBM offered IBM Watson Question and Answer (QA)
but in summer of 2015 this service replaced by four new services to support customize and embed Q&A applications.
The four replacement services recommended for different types of question and answer capabilities are:
 Natural Language Classifier – allows you to Interpret and classify natural language with confidence.
Natural Language Classifier – allows you to Interpret and classify natural language with confidence.
 Dialog – allows you to script a conversation and help walk a user through a process
Dialog – allows you to script a conversation and help walk a user through a process
 Retrieve and Rank – allows information retrieval with a machine learning model
Retrieve and Rank – allows information retrieval with a machine learning model
 Document Conversion – takes documents and ‘chunks them up” into smaller answer units to return as passages
Document Conversion – takes documents and ‘chunks them up” into smaller answer units to return as passages
based on your input data and requirements, you can choose one or combinations of these services to build a comprehensive and robust system.
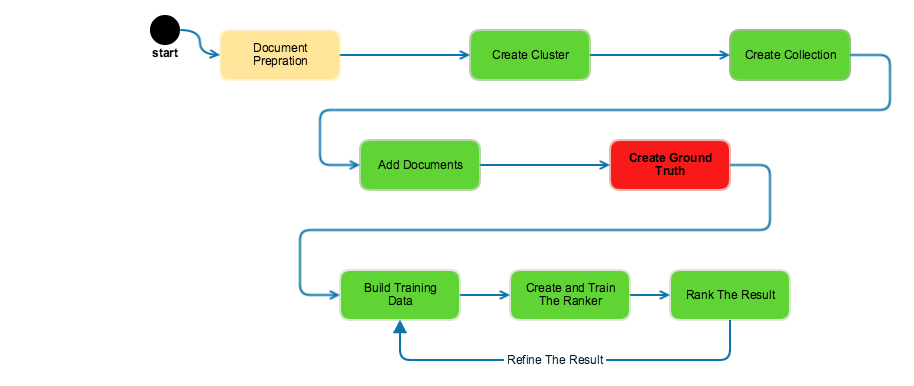
My Approach
I decide to use combination of Document Conversion and Retrieve and Rank Services. Document conversion service used to transform documents into Answer Units, and use those as input to
train the Retrieve and Rank Service.
Bluemix platform preparation
Before we start you need to prepare and setup your server and services. I decided to deploy my code in Bluemix as well, however you can just create your API in bluemix and deploy your code wherever you like (AWS :))
Login into you Bluemix account, in dashboard click on Service and APIs
you need to create two services Document Conversion and Retrieve and Rank and copy and paste the credentials. (it is pretty easy I am not going to explain it)

Document Preparation
The first and most important step is document preparation. The more disciplined you are in your handling of data, the more consistent and better results you are like likely to achieve. Watson
Document Conversion service helps you in this process so you don’t need to do it manually but we need to prepare our document for DC service.
You may ask how you can prepare a document? the answer is by providing related question as header of each paragraph.
DC service is sensitive to headers, it transform document to json format which contains list of answer_units dictionary. look at following example;
Document Sample
What is Watson? Watson is an artificially intelligent computer system capable of answering questions posed in natural language, developed in IBM's DeepQA project by a research team led by principal investigator David Ferrucci. Watson was named after IBM's first CEO and industrialist Thomas J. Watson. The computer system was specifically developed to answer questions on the quiz show Jeopardy! In 2011, Watson competed on Jeopardy! against former winners Brad Rutter and Ken Jennings. Watson received the first place prize of $1 million. How did it Work? Watson had access to 200 million pages of structured and unstructured content consuming four terabytes of disk storage including the full text of Wikipedia, but was not connected to the Internet during the game. For each clue, Watson's three most probable responses were displayed on the television screen. Watson consistently outperformed its human opponents on the game's signaling device, but had trouble responding to a few categories, notably those having short clues containing only a few words. And then, what happened? In February 2013, IBM announced that Watson software system's first commercial application would be for utilization management decisions in lung cancer treatment at Memorial Sloan–Kettering Cancer Center in conjunction with health insurance company WellPoint. IBM Watson's former business chief Manoj Saxena says that 90% of nurses in the field who use Watson now follow its guidance.Answer Units
{
"source_document_id":"",
"timestamp":"2016-04-15T08:42:37.055Z",
"media_type_detected":"application/wordprocessingml.document",
"metadata":[{"name":"Content-Type","content":"text/html; charset=UTF-8"},
{"name":"author","content":"Eva Luo"},
{"name":"publicationdate","content":"2015-08-20"}],
"answer_units":[
{
"id":"ff4da46f-b07a-4c12-aa2d-d5b0d3414c17",
"type":"h3",
"parent_id":"",
"title":"What is Watson?",
"direction":"ltr",
"content":[
{
"media_type":"text/plain",
"text":"Watson is an artificially intelligent computer ..."
}
]}],
"warnings":[]
}
Now we can use list of answer units for training Retrieve and Rank system.
Setup Retrieve and Rank System
This service helps users find the most relevant information for their query by using a combination of search and machine learning algorithms to detect “signals” in the data. Built on top of Apache Solr, developers load their data into the service, train a machine learning model based on known relevant results, then leverage this model to provide improved results to their end users based on their question or query.
Lets makes our hands dirty. if you have worked with Solr before, you may know we need our cluster and collection to index the data,
so the let’s setup them.I used Node.js for this project before you start you need to install
Node client library to use the Watson Developer Cloud services, a collection of REST APIs and SDKs that use cognitive computing
to solve complex problems. npm install watson-developer-cloud --save
the next and last pre step is create conf file;
var watson = require('watson-developer-cloud');
var retrieve_and_rank = watson.retrieve_and_rank({
username: '{username}',
password: '{password}',
version: 'v1'
});
var cluster_name = 'your_cluster_name'
var cluster_size = 'your cluster size'
module.exports.retrieve_and_rank = retrieve_and_rank
module.exports.cluster_name = cluster_name
module.exports.cluster_size = cluster_size
1. Create Cluster
To use the Retrieve and Rank service, you must create a Solr cluster. A Solr cluster manages your search collections, which you will create later.
conf.retrieve_and_rank.createCluster({
cluster_size: conf.cluster_size,
cluster_name: conf.cluster_name
},
function (err, response) {
if (err){
console.log('error:', err);
res.send(err)
}
else{
res.send(JSON.stringify(response, null, 2));
}
});
2. Upload Solr Configuration
The response includes
cluster_id and the cluster availability status. The cluster must be ready before you can use it. it takes about few minutes to become ready
but you can check the status through API.
After cluster become ready and before you can create collections you need to configure your cluster. The Solr configuration identifies how to index the documents so that you can search the important fields. you can download the sample solr config from here I may write separate post about solar config latter. you can upload one or many configuration to your retrieve and rank service.
var params = {
cluster_id: req.query.id,
config_name: 'mindvalley_config',
config_zip_path: './public/data/solr_config.zip'
};
conf.retrieve_and_rank.uploadConfig(params,
function (err, response) {
if (err){
console.log('error:', err);
res.send(err)
}
else{
console.log(JSON.stringify(response, null, 2));
res.send(JSON.stringify(response, null, 2));
}
});
3. Create Collection
A Solr collection is a logical index of the data in your documents. A collection is a way to keep data separate in the cloud. you need to assign one of the uploaded configuration to your collection
var params = {
cluster_id: '{cluster id you have from step 1}',
config_name: '{config name which is uploaded in step 2}',
collection_name: '{collection name}',
wt: 'json'
};
conf.retrieve_and_rank.createCollection(params,
function (err, response) {
if (err){
console.log('error:', err);
res.send(err);
}
else{
console.log(JSON.stringify(response, null, 2));
res.send(JSON.stringify(response, null, 2));
}
});
Now everything is ready to index (add) the question and answers generated by Document Conversion service into the collection.
jsonfile.readFile('./public/data/data.json', function (err, obj) {
obj = obj.answer_units
for (i in obj) {
var doc =
{
"id": obj[i].id,
"body": obj[i].content[0].text,
"title": obj[i].title
}
solrClient.add(doc, function (err, response) {
if (err) {
console.log('Error indexing document: ', err);
}
else {
console.log('Indexed a document.');
solrClient.commit(function (err) {
if (err) {
console.log('Error committing change: ' + err);
}
else {
console.log('Successfully committed changes.');
}
});
}
});
}
})
Ground truth is the collection of questions that are matched to answers. For the Retrieve and Rank service, you label the answers with their relevance to the question. The relevance label helps the ranker determine which features are the most useful. The questions, answers, and relevance labels are combined to create training data. we need to upload the training data to create and train a ranker.
The quality of training set is very important. Your training data need to have following quality criteria to be effective in improving the relevance of answers that are returned from the Retrieve and Rank service:
- The file must contain at least 49 unique questions.
- The number of records must be at least 50 times the number of fields that are identified in your Solr configuration. For example, if your collection defines five fields, you must have at least 250 records in your training data.
- At least two different relevance labels must exist in the data and those labels must be well represented. A label is well represented if it occurs at least once for every 100 unique questions.
The relevance file that we need to use in next step it suppose to be in the following CSV format:
"{question}","{answer_id1}","{relevance_label1}","{answer_id2}","{relevance_label2}","{...}"
- The answer ID is the unique key of a document which is indexed into your collection.
The relevance label is a non-negative integer (between zero and some upper limit). Higher numbers indicate higher relevance.
For example:“what similarity laws must be obeyed.”,“184”,“3”,“29”,“3”,“31”,“3” “what are the structural and aeroelastic problems.”,“12”,“4”,“15”,“3” “material properties of photoelastic materials.”,“463”,“4”,“462”,“2”,“497”,“0”
6 Build Training Data & Ranker
Good news is you are almost down :). IBM Watson team provide the python scripts which create a training set based on your ground truth csv.
The train.py Python script file takes the following format as input:
train.py -u {username:password} -i {relevance_file} -c {cluster_id} -x {collection_name}\
[-r {solr_rows_per_query}] [-n {ranker_name}]
The script creates a file in your working directory called trainingdata.txt. That file is used to create the ranker. When the script is finished, the script window displays a new ranker ID and its status. We’ll need it when we rerank results at runtime.
7 Time for ask question
Let’s test the system. you can search your collection with or without ranker. searching without ranker is useful to create a ground truth.
search without ranker (search solar standard)
var params = { cluster_id: req.query.id, collection_name: 'mindvalley_collection', wt: 'json', }; solrClient = conf.retrieve_and_rank.createSolrClient(params); console.log('Searching all documents.'); var query = solrClient.createQuery(); query.q(req.query.query); query.start(req.query.start) solrClient.search(query, function (err, searchResponse) { if (err) { console.log('Error searching for documents: ' + err); res.send(JSON.stringify(err, null, 2)); } else { console.log('Found ' + searchResponse.response.numFound + ' documents.'); res.send(JSON.stringify(searchResponse.response.docs, null, 2)); } });
Search With Ranker
var params = { cluster_id: req.query.id, collection_name: 'example_collection' }; var qs = require('qs'); solrClient = conf.retrieve_and_rank.createSolrClient(params); var ranker_id = req.query.ranker_id; var question = 'q=what is the basic mechanism of the transonic aileron buzz'; var query = qs.stringify({q: question, ranker_id: ranker_id, fl: 'id,title'}); solrClient.get('fcselect', query, function (err, searchResponse) { if (err) { console.log('Error searching for documents: ' + err); } else { console.log(JSON.stringify(searchResponse.response.docs, null, 2)); res.send(JSON.stringify(searchResponse.response.docs, null, 2)); } });
8 Help me to learn more
you can collect the user satisfaction level, regarding to the system answers in order to train your system and improve the results.
you can update your ground truth based on user input and repeat step 6.